hi guys, i needed some help with my codes. would appreciate whichever help i can have.
so i am creating this app to predict income from a dataset but while running the streamlit app, at the bottom it says Error: the variable ‘best_clf’ is not defined and i have been trying to find solution to it but of no help…can anyone help me to see my coding is my logic wise wrong like the placement of coding is wrong or the coding itself is wrong too?
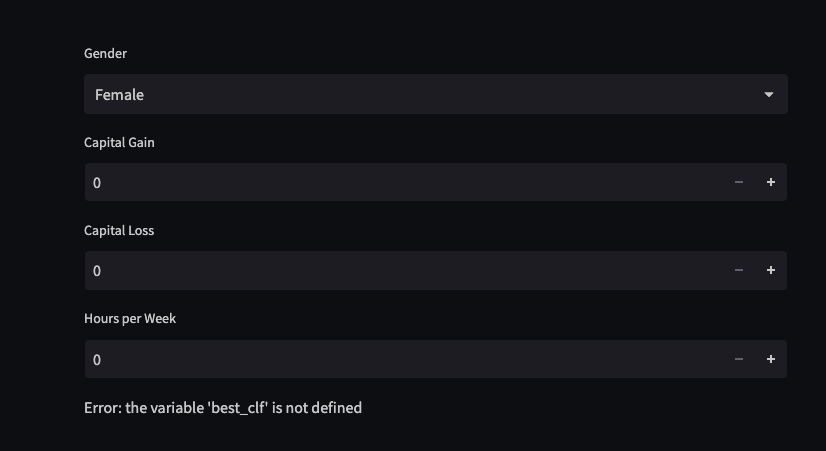
this is the coding to run the app:
import streamlit as st
from sklearn.tree import DecisionTreeClassifier
import joblib
# Load the model we trained previously
model = joblib.load('adult_income_model.pkl')
# Mapping the classes to numerical values
education_map = {
"10th": 0,
"11th": 1,
"12th": 2,
"1st-4th": 3,
"5th-6th": 4,
"7th-8th": 5,
"9th": 6,
"Assoc-acdm": 7,
"Assoc-voc": 8,
"Bachelors": 9,
"Doctorate": 10,
"HS-grad": 11,
"Masters": 12,
"Preschool": 13,
"Prof-school": 14,
"16 - Some-college": 15
}
workclass_map = {
"Federal-gov": 0,
"Local-gov": 1,
"Never-worked": 2,
"Private": 3,
"Self-emp-inc": 4,
"Self-emp-not-inc": 5,
"State-gov": 6,
"Without-pay": 7
}
occupation_map = {
"Adm-clerical": 0,
"Armed-Forces": 1,
"Craft-repair": 2,
"Exec-managerial": 3,
"Farming-fishing": 4,
"Handlers-cleaners": 5,
"Machine-op-inspect": 6,
"Other-service": 7,
"Priv-house-serv": 8,
"Prof-specialty": 9,
"Protective-serv": 10,
"Sales": 11,
"Tech-support": 12,
"Transport-moving": 13
}
nativecountry_map = {
"Cambodia": 0,
"Canada": 1,
"China": 2,
"Columbia": 3,
"Cuba": 4,
"Dominican Republic": 5,
"Ecuador": 6,
"El Salvadorr": 7,
"England": 8,
"France": 9,
"Germany": 10,
"Greece": 11,
"Guatemala": 12,
"Haiti": 13,
"Netherlands": 14,
"Honduras": 15,
"HongKong": 16,
"Hungary": 17,
"India": 18,
"Iran": 19,
"Ireland": 20,
"Italy": 21,
"Jamaica": 22,
"Japan": 23,
"Laos": 24,
"Mexico": 25,
"Nicaragua": 26,
"Outlying-US(Guam-USVI-etc)": 27,
"Peru": 28,
"Philippines": 29,
"Poland": 30,
"Portugal": 31,
"Puerto-Rico": 32,
"Scotland": 33,
"South": 34,
"Taiwan": 35,
"Thailand": 36,
"Trinadad&Tobago": 37,
"United States": 38,
"Vietnam": 39,
"Yugoslavia": 40
}
maritalstatus_map = {
"divorced": 0,
"married": 1,
"passed on": 2,
"single": 3
}
relationship_map = {
"Husband": 0,
"Not-in-family": 1,
"Other-relative": 2,
"Own-child": 3,
"Unmarried": 4,
"Wife": 5
}
race_map = {
"Amer Indian Eskimo": 0,
"Asian Pac Islander": 1,
"Black": 2,
"Other": 3,
"White": 4
}
gender_map = {
"Female": 0,
"Male": 1
}
# Create a UI function
def predict_income():
# Get input data from the user
age = st.number_input("Age", min_value=0, max_value=100, value=30)
education = st.selectbox("Education", list(education_map.keys()))
education = education_map[education]
workclass = st.selectbox("Work Class", list(workclass_map.keys()))
workclass = workclass_map[workclass]
occupation = st.selectbox("Occupation", list(occupation_map.keys()))
occupation = occupation_map[occupation]
nativecountry = st.selectbox("Native Country", list(nativecountry_map.keys()))
nativecountry = nativecountry_map[nativecountry]
maritalstatus = st.selectbox("Marital Status", list(maritalstatus_map.keys()))
maritalstatus = maritalstatus_map[maritalstatus]
relationship = st.selectbox("Relationship", list(relationship_map.keys()))
relationship = relationship_map[relationship]
race = st.selectbox("Race", list(race_map.keys()))
race = race_map[race]
gender = st.selectbox("Gender", list(gender_map.keys()))
gender = gender_map[gender]
capital_gain = st.number_input("Capital Gain", min_value=0, max_value=100000)
capital_loss = st.number_input("Capital Loss", min_value=0, max_value=100000)
hours_per_week = st.number_input("Hours per Week", min_value=0, max_value=100)
# Use the model to make a prediction
try:
prediction = best_clf.predict([[age, education, workclass, occupation, nativecountry, maritalstatus, relationship, race, gender, capital_gain, capital_loss, hours_per_week]])
except NameError:
st.write("Error: the variable 'best_clf' is not defined")
else:
if prediction == 0:
st.success("The person is less likely to make over 50K per year")
else:
st.success("The person is more likely to make over 50K per year")
# Create the Streamlit app
st.title("Income Prediction App")
st.write("Enter your details and find out your predicted income.")
predict_income()
and this is the coding for my model :
import pandas as pd
import numpy as np
import joblib
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score, f1_score
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.3, random_state = 100)
# Create an instance of the decision tree classifier
dt_clf = DecisionTreeClassifier(random_state = 100)
# Define the parameters to be tuned
param_grid = {'criterion': ['gini', 'entropy'],
'max_depth': [3, 4, 5, 6, 7],
'min_samples_leaf': [5, 10, 20, 30],
'min_impurity_decrease': [0.0, 0.1, 0.2, 0.3]}
# Create a GridSearchCV object
grid_search = GridSearchCV(dt_clf, param_grid, cv=5)
# Fit the GridSearchCV object to the data
grid_search.fit(X_train, y_train)
# make predictions on the test data using the best estimator
best_clf = grid_search.best_estimator_
y_pred = best_clf.predict(X_test)
# Train the model using the best parameters from the grid search
best_clf.fit(X_train, y_train)
# Predict the target variable using the best estimator
predictions = best_clf.predict(X_test)
# Save the trained model to a file so we can use it in other programs
joblib.dump(best_clf, 'adult_income_model.pkl')
# Print the accuracy of the model
print("Accuracy: {:.2f}%".format(accuracy_score(y_test, y_pred) * 100))
# Calculate the f1 score
f1 = f1_score(y_test, y_pred)
print("F1 Score:", f1)
# Perform K-fold cross-validation
kfold = KFold(n_splits=5, shuffle=True)
scores = cross_val_score(best_clf, X_train, y_train, cv=kfold)
print("Cross Validation Score: %.2f%% (%.2f%%)" % (scores.mean()*100, scores.std()*100))
print("Best Score:", grid_search.best_score_)
# Print the best parameters
print("Best Parameters:", grid_search.best_params_)