Hello Streamlit community!
I’m excited to introduce you to my project, Crawlit. It’s a web crawler built on Scrapy, enhanced with a Streamlit user interface to visualize and analyze the results.

Key Features:
- Web Crawler: Uses Scrapy (and Crowl.tech) to navigate and gather data from specified websites.
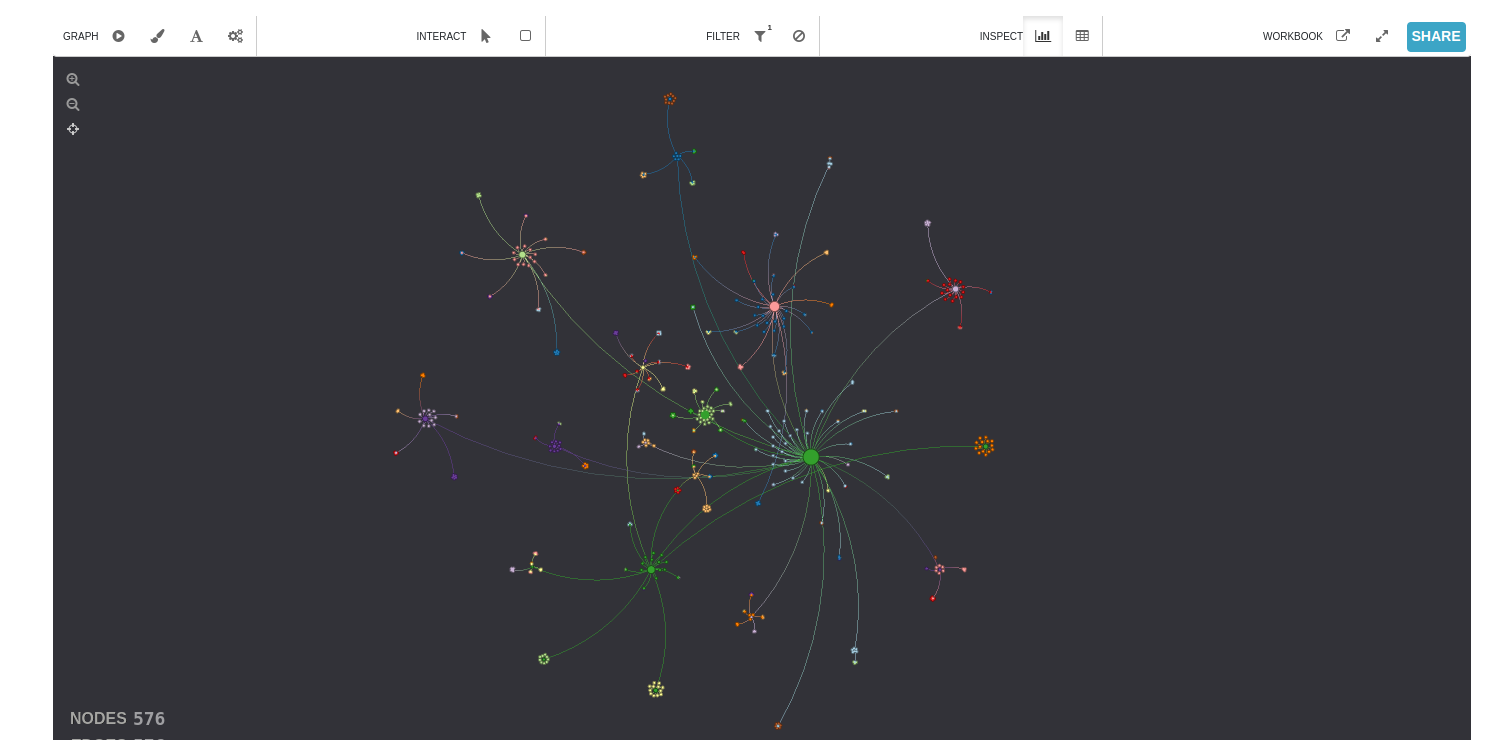
- Streamlit Interface: Provides interactive visualization and analysis of the collected data, including a distribution of PageRanks.
- CSV Export: Offers the capability to export the gathered data in CSV format for further processing.
- PageRank: In this project, we employ a method to compute the PageRank of various pages, drawing inspiration from the original algorithm and incorporating the concept of the reasonable surfer.
- Visualization with ECharts: We utilize ECharts, an open-source visualization library, to showcase the distribution of PageRanks of our crawled web pages, the distribution of response statuses, links by depth, among other insights.
How to Use?
- Clone the repository:
git clone https://github.com/drogbadvc/crawlit.git - Navigate to the project directory and install dependencies:
pip install -r requirements.txt - Run the project with:
streamlit run graph-streamlit.py - Open your browser at:
http://localhost:8501after launching Streamlit.
For more details, please refer to the documentation on GitHub.
I’d greatly appreciate your feedback and suggestions to enhance this project. Thank you for your attention, and happy exploring!