I have a problem with this application
https://dimitheodoro-lung-nodule-detection-main-n1ziqn.streamlitapp.com/
I download the weights from Google Drive , but it always does not find any nodule. It was a memory error in the beginning, but is this the cause?
How can I make it work??
Hi @dimitheodoro, welcome to the Streamlit community! ![]()
I see that the weights are re-downloaded with every interaction a user has with the app. What you can do is cache the weight and model with @st.experimental_singleton, so that the weights and model are downloaded / loaded just once and used across user sessions.
To do so, replace lines 13-22 of main.py with the following:
@st.experimental_singleton
def download_weights(url):
gdown.download(url, "weight_path", quiet=False)
@st.experimental_singleton
def load_model():
print(" MODEL LOADED !!!")
return torch.load("weight_path", map_location=device)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
url = "https://drive.google.com/uc?export=download&id=1XiaNFXISnfVMmbvRGlTxFKVLV6l5-fZy"
download_weights(url)
model = load_model()
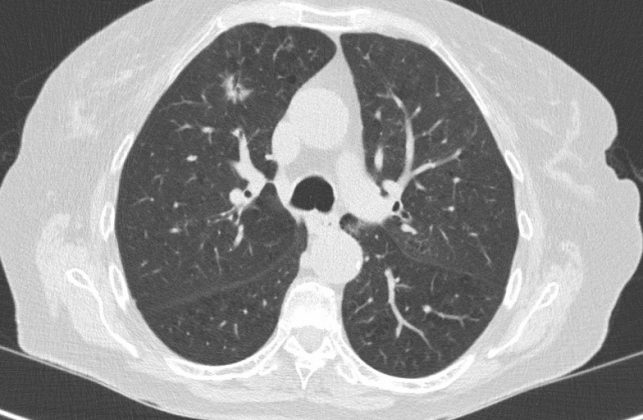
I think once you make the above change and reboot the app, uploading this image should result in bounding boxes around detected nodules like so:

Best, ![]()
Snehan
1 Like
Thanks for the quick reply.!!!
I rebooted after the changes but the problem remains.
When I reboot I never have the balloons launch to understand that all is ok. I just wait and without any sign i load the image, Why this??
I think I will delete it and deploy it again.!!!
How did it work in your case???
Could it be an issue with the RAM of the cloud service?
I guess the weights take a lot of space.
I was wandering why using st.experimental_singleton rather than st.experimental_memo.
Reading at this post: https://blog.streamlit.io/new-experimental-primitives-for-caching/, it seems to be that as he is just downloading data, st.experimental_memo should fit better, isn’t it?
I was wandering why using st.experimental_singleton rather than st.experimental_memo.
Reading at this post: https://blog.streamlit.io/new-experimental-primitives-for-caching/, it seems to be that as he is just downloading data, st.experimental_memo should fit better, isn’t it?
The screenshot from my earlier reply was from my local PC, not Streamlit Cloud. Since I was sure the app works locally, my last effort was to pin the packages in requirements.txt to the same versions as I had installed locally. That worked on Streamlit Cloud!
Replace your requirements.txt in the repo with the following, and delete and de-deploy your app:
streamlit==1.10.0
numpy==1.23.1
opencv-python-headless==4.6.0.66
albumentations==1.2.0
Pillow==9.1.0
torch==1.11.0
torchvision==0.12.0
gdown==4.5.1
Doing so made the app work successfully on Cloud:

{kind=link}
@oltipreka You’re right! st.experimental_memo is indeed the better fit in this case while storing the downloaded weights.
1 Like
Thank you @snehankekre this was the case!
Despite that, after 3-4 predictions it breaks down!!
anyway !!
Thanks for your support!
I am not quite sure heeee !! ![]()
But form the blog, it seems like st.experimental_singleton is more appropriate to db connections and similar, so that the app does not connects each times a users loads the page, whereas for downloading data memo should be better.
At least, this is how I understand it.
Unfortunately, the app might be exhausting the allocated 1GB of RAM on Streamlit Cloud after a few predictions. ![]()
Try adding the ttl parameter, which sets the:
The maximum number of seconds to keep an entry in the cache, or None if cache entries should not expire. The default is None.
In my understanding, the app keeps in cash more info from the app, so after a number of searches, it gets full.
I experience the same issue with a Web App I deploy using render (another service).
This topic was automatically closed 365 days after the last reply. New replies are no longer allowed.