If you scroll down any of the pages, the links on the right stay in place. Not only that, the links will stay within their container so if you had some footer content after the column containers, the links will not end up covering or on top of it when you scroll all the way down.
In the example, I shared, I did this purely with markup in an st.markdown with unsafe_allow_html=True.
For another little project, I wanted to just float a container with vertically stacked Streamlit elements/widgets/components like st.title and st.radio.
I found a solution that works like a charm (in browsers that support css :has() psuedo-class so not firefox) and its very simple to implement and use. To implement you need:
Note: Because containers add gaps between st elements, an additional gap will be added when you add the above. To sortof get around this, you can place the above after or before the content depending on what you prefer appearance-wise.
This is simple enough of a solution that I am not sure it needs to be turned into a component. Would anyone be interested in a component that adds the css and makes adding the div as simple as calling a function like float() ?
I am very interested in this idea- thanks very much for posting.
I can’t get it working though?
import streamlit as st
html_style = '''
<style>
div:has( >.element-container div.floating) {
display: flex;
flex-direction: column;
position: fixed;
}
div.floating {
height:0%;
}
</style>
'''
st.markdown(html_style, unsafe_allow_html=True)
####
with st.container():
st.write("This text should not float.")
####
with st.container():
st.write("This text should float")
st.markdown('<div class="floating"></div>', unsafe_allow_html=True)
I have used different browsers but this just gives me two regular containers:
Hey! Just caught sight of your comment. Im not able to test your example right now so i cant say for sure but one thing im noticing in your example is that you have no reason to scroll past the content added (two containers). If you look at the example in the gif at the bottom of my post you will see that on the left is a lot of content that stretches further down than the content on the right. Such that if the container on the left side wasnt floating, then you would scroll past it when you scrolled to the bottom. In your case, the floating container is the end of your page/content…so you dont have the situations where the floating effect could be observed.
The main situation this floating effect is made for is when you have multiple columns of content that are different lengths and you want some of the content in the shorter colume to always be visible as you scroll down.
Your alternative is similar to how I originally did it. However, you need to remove the last bit in the css that sets the height of the floating div to zero.
There are two thing to note when adding floating content as html markup like in your approach. One, its harder to add streamlit components to the floating div and two, you can avoid using the :has css selector to acheived the effect which means better browser support (Firefox doesnt support the selector by default - you have to change browser settings). So there is a weakness and a strength to this approach.
To remove the :has in your example, change the code to something like:
import streamlit as st
t = 'A faster way to build and share data apps'
html_style = '''
<style>
div.floating {
display: flex;
flex-direction: column;
position: fixed;
}
</style>
'''
st.markdown(html_style, unsafe_allow_html=True)
col1, col2 = st.columns([9, 2])
with col1:
for i in range(0, 30):
st.header("Today's news")
st.write(t)
with col2:
st.markdown(
'''
<div class="floating">
<a href='https://streamlit.io/'>Hello Streamlit</a>
<a href='https://streamlit.io/'>Hello Streamlit</a>
<a href='https://streamlit.io/'>Hello Streamlit</a>
</div>
''',
unsafe_allow_html=True
)
Perhaps there is a way to avoid using the :has selector AND be able to also add Streamlit components to the floating container!
Finally got around to doing it! Thanks for the feedback and interest!
Check out the project here:
One thing I would like to improve is remove the need for initialization so if anyone has an idea on how to accomplish that let me know or make a pull request.
Hello bouzidanas, I was just testing streamlint_ Float, perhaps it can also implement floating search boxes, but for components in st. container, an additional CSS attribute needs to be added:
That sounds very interesting! I tested the change you suggested, but I just get the same effect. So Im not sure I fully understand. What happens to the search box when the z-index is not set to a high number? Does it get overlapped somehow?
import pandas as st
from streamlit_float import *
# initialize float feature/capability
float_init()
co1 = st.container()
with co1:
st.text_input(label='Global Search')
float_parent()
co2 = st.container()
with co2:
for i in range(0, 20):
st.header("**Today's news**")
st.write("Streamlit turns data scripts into shareable web apps in minutes.")
If you dont mind, can you fork the repository, make the css change (add z-index: 99;) and then make a pull request? That way you get credit for your addition.
Thanks to discussions here and contributions from members (like @lkdd-ao) who are finding more and more use cases for this module, streamlit-float has significantly improved. I am happy to announce the first release version: Version 0.2.6!
New features:
Target floating containers with your own CSS!
You can now add your own CSS to any container you float by providing a string containing the CSS!
The newly added float_box function takes the markdown you provide it and puts it in a newly created floating div container. This function also provides direct access (via its arguments) to several CSS parameters/attributes allowing you to easily adjust size, position, background, and border as well as add box-shadows and transitions.
Example:
import streamlit as st
from streamlit_float import *
float_init()
if "show" not in st.session_state:
st.session_state.show = True
# Page content
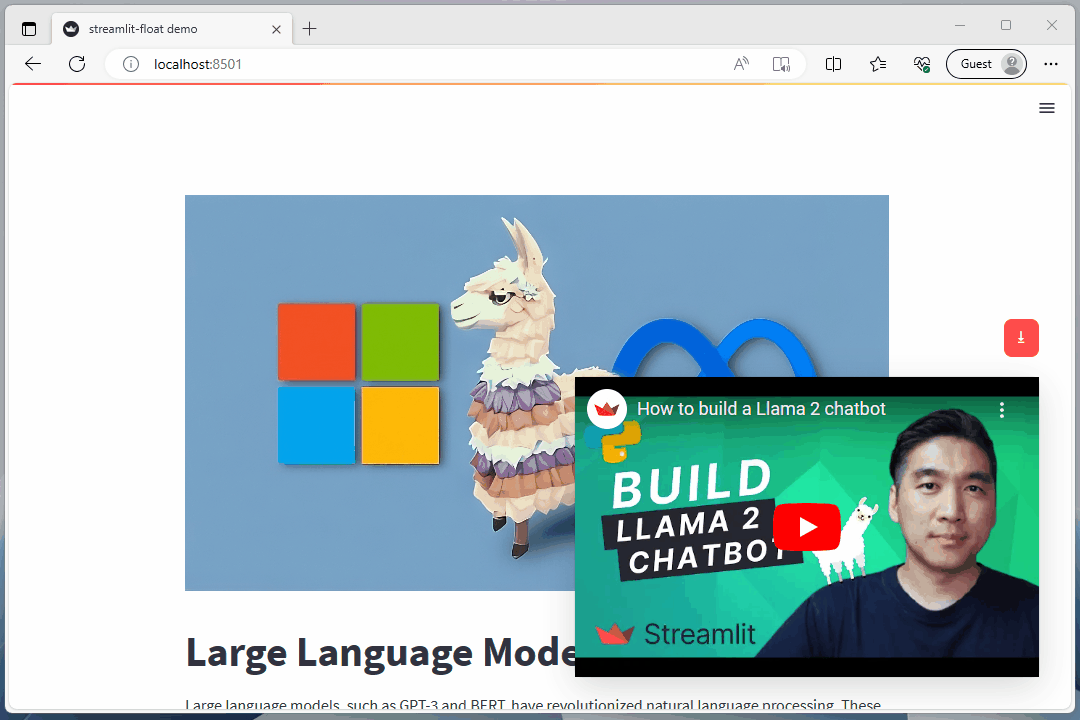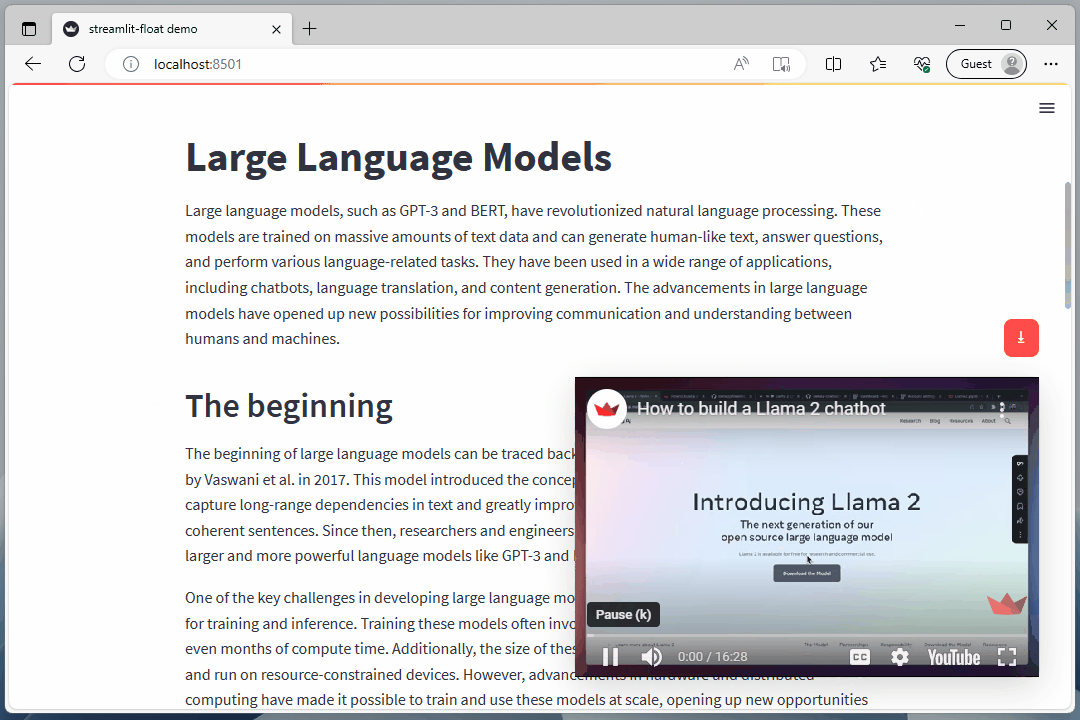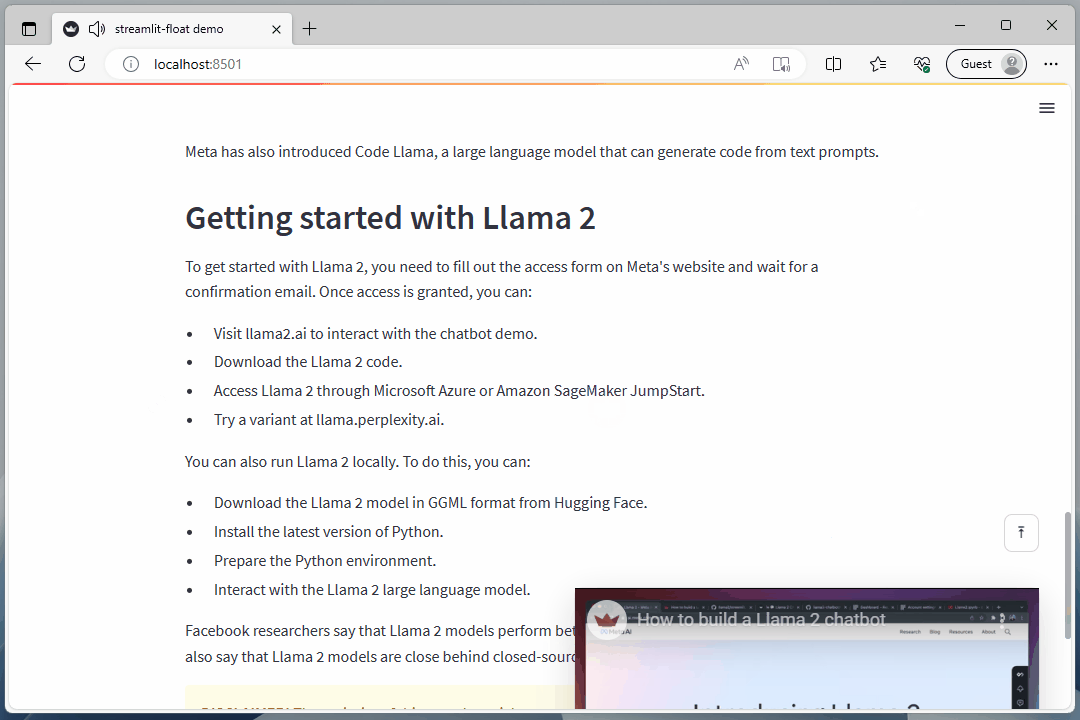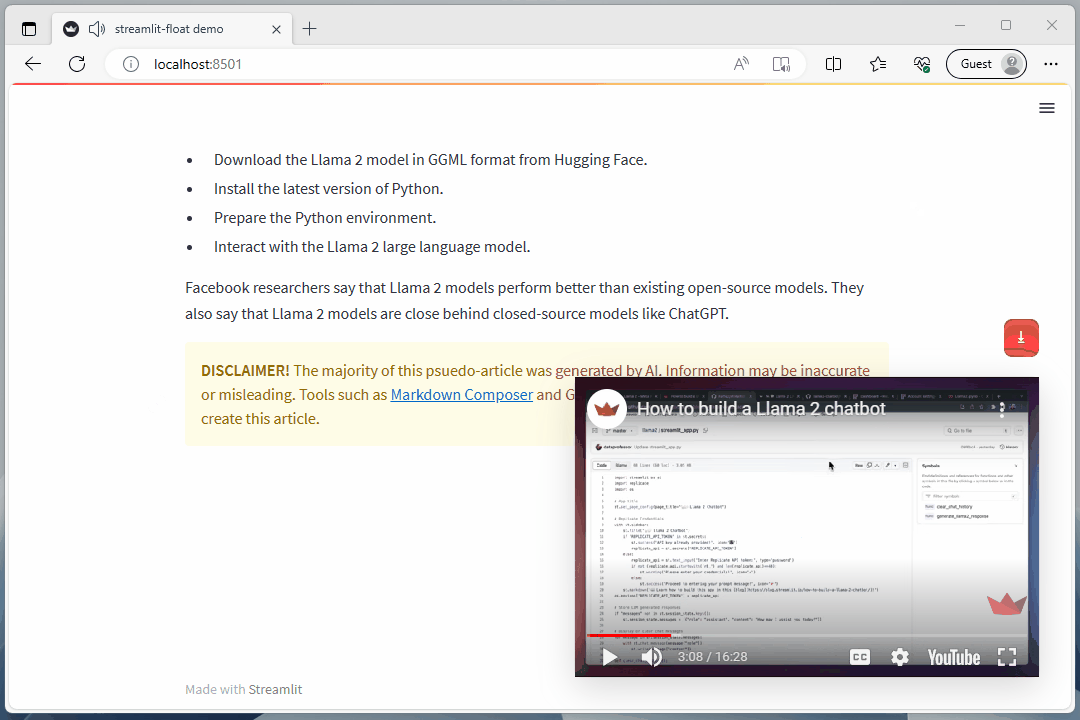
st.markdown('''# Large Language Models
Large language models, such as GPT-3 and BERT, have revolutionized natural language processing. These models are trained on massive amounts of text data and can generate human-like text, answer questions, and perform various language-related tasks. They have been used in a wide range of applications, including chatbots, language translation, and content generation. The advancements in large language models have opened up new possibilities for improving communication and understanding between humans and machines.
## The beginning
The beginning of large language models can be traced back to the development of the Transformer model by Vaswani et al. in 2017. This model introduced the concept of self-attention, which allows the model to capture long-range dependencies in text and greatly improves its ability to understand and generate coherent sentences. Since then, researchers and engineers have built upon this foundation to create even larger and more powerful language models like GPT-3 and BERT.
One of the key challenges in developing large language models is the computational resources required for training and inference. Training these models often involves using thousands of GPUs and weeks or even months of compute time. Additionally, the size of these models can make them difficult to deploy and run on resource-constrained devices. However, advancements in hardware and distributed computing have made it possible to train and use these models at scale, opening up new opportunities for natural language processing.
## Enter the big players
The big players in AI, such as Microsoft, Google, and Facebook, have played a crucial role in bringing the resources needed to accelerate progress in large language models (LLMs). These companies have invested heavily in research and development, as well as in building the necessary infrastructure to train and deploy these models.
Microsoft, for example, has made significant contributions to the field of natural language processing through projects like Microsoft Research NLP and the development of the Turing NLG language model. They have also developed Azure Machine Learning, a cloud-based platform that provides the computational resources and tools needed to train and deploy large language models at scale.
Google, on the other hand, has been at the forefront of LLM research with projects like Google Brain and Google Research. They have developed models like BERT and T5, which have achieved state-of-the-art performance on a wide range of natural language processing tasks. Google's cloud platform, Google Cloud, provides the infrastructure and tools necessary for training and deploying large language models.
Meta has also made significant contributions to the field of natural language processing through projects like PyTorch and the development of models like RoBERTa. They have also invested in building powerful computing infrastructure, such as the FAIR (Facebook AI Research) cluster, which enables researchers to train and experiment with large language models.
These companies have not only brought the necessary computational resources to the table but have also contributed to the research and development of novel techniques and architectures for improving the performance and efficiency of large language models. Their contributions have helped to push the boundaries of what is possible in natural language processing and have accelerated progress in the field.
## Llama 2: Partnership between Microsoft and Meta
Llama 2 is a collection of open-source large language models (LLMs) developed by Meta AI. The models range in size from 7 billion to 70 billion parameters and are designed to perform well on various language processing tasks. Llama 2 is available for free for research and commercial use.
Llama 2 is the result of a partnership between Meta and Microsoft. The models are optimized for dialogue use cases and can be used to create a ChatGPT-like chatbot.
Llama 2 is considered a game-changer for the adoption and commercialization of LLMs because of its comparable performance with much larger models and its permissive open-source license. The license allows the use and distribution of Llama 2 in commercial applications.
Meta has also introduced Code Llama, a large language model that can generate code from text prompts.
## Getting started with Llama 2
To get started with Llama 2, you need to fill out the access form on Meta's website and wait for a confirmation email. Once access is granted, you can:
- Visit llama2.ai to interact with the chatbot demo.
- Download the Llama 2 code.
- Access Llama 2 through Microsoft Azure or Amazon SageMaker JumpStart.
- Try a variant at llama.perplexity.ai.
You can also run Llama 2 locally. To do this, you can:
- Download the Llama 2 model in GGML format from Hugging Face.
- Install the latest version of Python.
- Prepare the Python environment.
- Interact with the Llama 2 large language model.
Facebook researchers say that Llama 2 models perform better than existing open-source models. They also say that Llama 2 models are close behind closed-source models like ChatGPT.\n
''')
st.warning("**DISCLAIMER!** The majority of this psuedo-article was generated by AI. Information may be inaccurate or misleading. Tools such as [Markdown Composer](https://markdown-composer.streamlit.app/) and Google's [Generative AI search](https://blog.google/products/search/generative-ai-search/) were used to create this article.")
# Container with expand/collapse button
button_container = st.container()
with button_container:
if st.session_state.show:
if st.button("⭳", type="primary"):
st.session_state.show = False
st.experimental_rerun()
else:
if st.button("⭱", type="secondary"):
st.session_state.show = True
st.experimental_rerun()
# Alter CSS based on expand/collapse state
if st.session_state.show:
vid_y_pos = "2rem"
button_css = float_css_helper(width="2.2rem", right="2rem", bottom="21rem", transition=0)
else:
vid_y_pos = "-19.5rem"
button_css = float_css_helper(width="2.2rem", right="2rem", bottom="1rem", transition=0)
# Float button container
button_container.float(button_css)
# Add Float Box with embedded Youtube video
float_box('<iframe width="100%" height="100%" src="https://www.youtube.com/embed/J8TgKxomS2g?si=Ir_bq_E5e9jHAEFw" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>',width="29rem", right="2rem", bottom=vid_y_pos, css="padding: 0;transition-property: all;transition-duration: .5s;transition-timing-function: cubic-bezier(0, 1, 0.5, 1);", shadow=12)
I have just completed adding some new features and updating some of the existing ones!
NEW Float Dialog container
The float_dialog function creates a streamlit container that is manipulated to have the appearance and behavior of a simple dialog box. This function takes a boolean which shows or hides the dialog box.
Example:
import streamlit as st
from streamlit_float import *
# Float feature initialization
float_init()
# Initialize session variable that will open/close dialog
if "show" not in st.session_state:
st.session_state.show = False
# Button that opens the dialog
if st.button("Contact us"):
st.session_state.show = True
st.experimental_rerun()
# Create Float Dialog container
dialog_container = float_dialog(st.session_state.show, background="var(--default-backgroundColor)")
# Add contents of Dialog including button to close it
with dialog_container:
st.header("Contact us")
name_input = st.text_input("Enter your name", key="name")
email_input = st.text_input("Enter your email", key="email")
message = st.text_area("Enter your message", key="message")
if st.button("Send", key="send"):
# ...Handle input data here...
st.session_state.show = False
st.experimental_rerun()
Note that the float_init function calls a function called theme_init which grabs some of the default theme values like background color. This theme_init then creates CSS variables with those values. The new CSS variables are:
These CSS variables become available to you when theme_init is called and can be used in any CSS you add via st.markdown.
Note that in the example above, one of the CSS variables is used to set the background of the dialog to be the same as the app.
Another development that may be of interest is the addition of two new configuration arguments to the float_dialog function: transition_from and transition_to. Each argument accepts one of three possible values: top, bottom, and center. These values change where the dialog container pops into view from and where its final position will be once the transition ends.
"top" → "top"
"top" → "center"
"bottom" → "bottom"
"center" → "center"
Choosing "center" for both is recommended for cases where speed and simplicity (no frills) are preferred.
NEW Float Overlay
The float_overlay function creates a simple overlay (using float_box under the hood) that blurs and dims everything underneath it. By default, the overlay is placed on top of everything but the header bar. This can be changed using the function’s z_index argument.
The idea here is that you can use streamlit-float functions to float specific content and selected things above the overlay while everything else is placed underneath (becoming less visible and inaccessible).
Example:
import streamlit as st
from streamlit_float import *
# Float feature initialization
float_init()
# Initialize session variable that will open/close dialog
# We start the app with our tutorial overlay on
if "show" not in st.session_state:
st.session_state.show = True
# add overlay
float_overlay(st.session_state.tutorial, alpha=0.2, z_index="999980")
# Add container with close overlay button
if st.session_state.show:
close_button_container = st.container()
with close_button_container:
if st.button("Close", key="close"):
st.session_state.show= False
st.experimental_rerun()
# Float close button container
close_button_container_css = float_css_helper(width="2.2rem", right="4rem", bottom="2rem", z_index="999999")
close_button_container.float(close_overlay_css)
# Add content that will sit on top of overlay
float_box('<div style="height:fit-content;">Click close button to exit tutorial </div><div>↴</div>', height="2rem", right="2.7rem", bottom="7.5rem", background="transparent", css="min-width: 25%; width:fit-content;flex-direction: row;justify-content: right;color: #ffffff;font-size:1.8rem;z-index:999999;gap:0.5rem;")
This is great. Thank you so much. I want to have a page with two columns on which on one I display a pdf file and the other I display a chat interface but the chat input is always above. I tried with your float on the column for the chat but then everything floats to the bottom including the chat messages. I would like to have only the chat input on the bottom of the column and the chat messages displaying on top like it happens normal without a column. How could I do this?
In the chat column, dont float the column. Add a st.container inside the chat column at the end after all the messages and float this container instead. This is the container where you place the input. You can add css to ensure this input container is positioned at the bottom of the column.
Hello bouzidanas, I am not sure if the ‘transition’from’ and ‘transition_to’ parameters of ‘float_dialog’ can be used in the latest version, and I did not find it.
Another good news is that I tried using ‘float_parent’ to design a topped filter, and it looks pretty good.