Hello, guys!
our project team made an GitHub Repository ChatBot.
GitHub QA ChatBot is
- Question-Answering with github’s speicific repository
- You can visualize folder structure and file-content
Chat-GPT can answer information in various fields. However, Chat-GPT is not learning about the latest technology framework, the latest code, so we have to study while looking at the GitHub repository. Based on these points, the app was developed.
we will close our demo-app if there costs lots of open-ai-api-key ![]() But we want to share it with a lot of people who are my strength, and we want to keep this service for a long time.
But we want to share it with a lot of people who are my strength, and we want to keep this service for a long time.
And Here is Demo-app link and Github repository link!
For Whom?
- For whom who wants to lean new repository that chat-gpt cannot answer about the information
- For whom who wants to learn coding by viewing github - repository


The tech stack is like this
Github Restapi - Repository Info by DFS algorithm
LangChain - Communication Data with GPT-3.5-turbo
VectorDB - FAISS ( mmr algorithm use)
Streamlit - Deployment
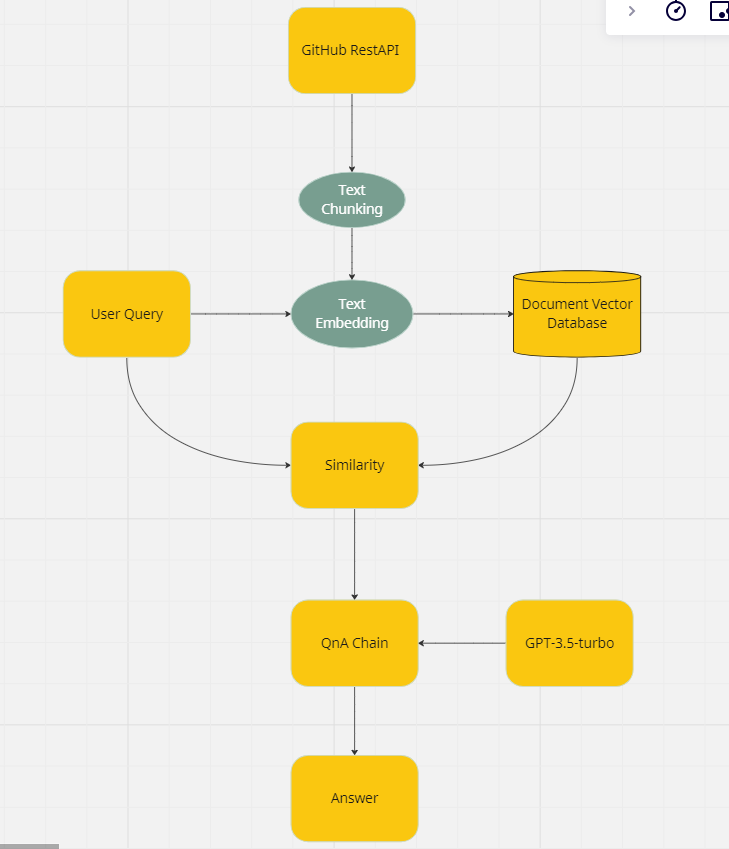
How it works?
- QA Chat Bot Page
1. Get User and Repository Information by Github Rest api and we get the information by dfs algorithm. We can get an data with
{file_name_1 : file_content, file_name_2 : file_content, file_name_3: file_content}
2. Change Dictionary data types to document types.
We also manually add the data which involes the folder structure by python anytree.
So the QA chat bot can also answer about the folder structure.
3. Document Chunking with 1000 tokens and 0 overlap with FAISS.
- we want to use pinecone vector Database . But because we use free tier.
we can't handler multi user by pinecone.
4. Question Answering with LangChain QA Retriever
- Folder Structure Page
1. Get data with pip's anytree
2. By DFS , we can get an tree structure
3. For visualizing we used streamlit's agraph library
What’s the Limitation?
- We use Github Restapi which limits 5000 times per hour
- OPEN AI API KEY Cost
- Until now , we can get a memory in the LangChain QA Retriever, but it can't utilize based on what's in its memory.
- If the repository you want to analyze has lots of files, it can takes lots of times
Finally , I want to say thanks for streamlit community.
When there was something I didn’t know, I asked questions to Streamlit community
The people of streamlit community responded kindly.